X-Engine is an online transaction processing (OLTP) database-oriented storage engine that is developed by the Database Products Business Unit of Alibaba Cloud. X-Engine is widely used in a number of business systems within Alibaba Group to reduce costs. These systems include the transaction history database and the DingTalk chat history database. In addition, X-Engine is a crucial database technology that empowers Alibaba Group to withstand bursts of traffic that can surge to hundreds of times greater than average during Double 11, a shopping festival in China.
The X-Engine engine is phased out. For more information, see [EOS/Discontinuation] ApsaraDB RDS for MySQL instances that run the X-Engine storage engine are no longer available for purchase from November 1, 2024.
Background information
X-Engine is designed to help Alibaba Group run internal workloads. Alibaba Group has been deploying MySQL databases at scale since 2010. However, a large volume of data that grows exponentially year by year continues to impose the following challenges on these databases:
Process highly concurrent transactions.
Store large amounts of data.
To increase the processing capabilities and storage capacity, you can add servers on which more databases can be created. However, this method is inefficient. Alibaba Cloud aims to use technical means to maximize performance with minimal resources.
The performance of the conventional database architecture is carefully studied. Michael Stonebreaker, a leader in the database field and a winner of the Turing Award, wrote a paper titled OLTP Through the Looking Glass, and What We Found There on this topic. In the paper, he points out that conventional general-purpose relational databases spend less than 10% of the time in actually processing data. The remaining 90% of the time is wasted on other work, such as waiting for locked resources, managing buffers, and synchronizing logs.
This is caused by significant changes to the hardware systems that we depend on in recent years. These include multi-core and many-core CPUs, new processor architectures such as the cache-only memory architecture (COMA) and the non-uniform memory access (NUMA), various heterogeneous computing devices such as GPUs and field-programmable gate arrays (FPGAs). However, the database software built on these hardware systems has not changed much. Such software includes the mechanism that fixes page sizes based on B-tree indexing, the mechanism that processes transactions and restores data by using the recovery and isolation exploiting semantics (ARIES) algorithms, and the concurrency control mechanism based on independent lock managers. These software mechanisms are designed based on slow disks and therefore cannot achieve the potential performance of the preceding hardware systems.
Alibaba Cloud developed X-Engine to support the requirements of the hardware systems that are used today.
Architecture
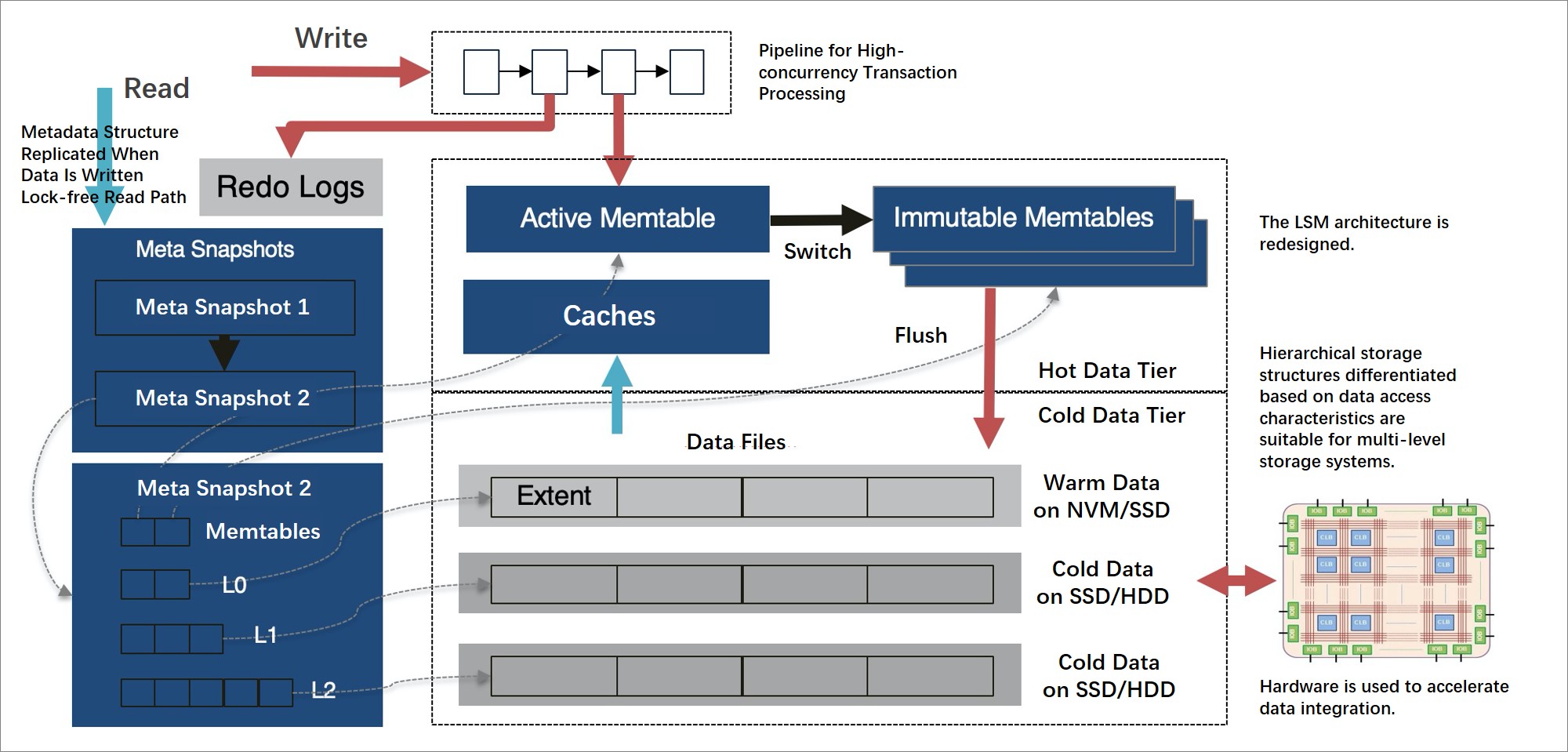
With the pluggable storage engine of MySQL, X-Engine can be seamlessly integrated with MySQL and use the tiered storage architecture.
X-Engine is designed to store large amounts of data, increase the capability of processing concurrent transactions, and reduce storage costs. In most scenarios with large amounts of data, the data is not evenly accessed. Frequently accessed data, which is called hot data, accounts for only a small proportion. X-Engine divides data into multiple levels based on the access frequency. In addition, X-Engine determines storage structures and writes the data to appropriate storage devices based on the access characteristics of each level of data.
X-Engine uses the log-structured merge-tree (LSM tree) architecture that is redesigned for tiered storage.
X-Engine stores hot data and updated data in the memory by using a number of memory database technologies to expedite the execution of transactions. These technologies include lock-free index structures and append-only data structures.
X-Engine uses a transaction processing pipeline mechanism to run multiple transaction processing stages in parallel. This significantly increases throughput.
Less frequently accessed data, which is called cold data, is gradually deleted or merged to persistent storage levels, and stored in tiered storage devices, such as NVMs, SSDs, and HDDs.
A number of improvements are made to compactions that impose a significant impact on performance.
The data storage granularity is refined based on the concentration of data update hotspots. This ensures that data is reused as much as possible in the compaction process.
The hierarchy of the LSM tree is refined to reduce I/O and computing costs and to minimize the storage that is consumed by compactions.
More fine-grained access control and caching mechanisms are used to optimize read performance.
The architecture and optimization technologies of X-Engine are summarized in a paper titled X-Engine: An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing. The paper was presented at the 2019 SIGMOD Conference, an international academic conference in the database field. This was the first time that a company from the Chinese mainland published technological achievements in OLTP database engines at an international academic conference.
Highlights
FPGA hardware is used to accelerate compactions and further maximize the performance of database systems. This marks the first time that hardware acceleration is applied to the storage engine of an OLTP database. The achievement is summarized in a paper titled FPGA-Accelerated Compactions for LSM-based Key Value Store. The paper was accepted by the 18th USENIX Conference on File and Storage Technologies (FAST'20) in 2020.
The data reuse technology is used to reduce the costs of compactions and mitigate the performance jitters that are caused by data deletion from the cache.
Queued multi-transaction processing and pipeline processing are used to reduce the thread context switching overheads and calculate the task ratio in each stage. This streamlines the entire pipeline and increases transaction processing performance by more than 10 times compared with other similar storage engines such as RocksDB.
The copy-on-write technique is used to prevent data pages from being updated when the data pages are read. This allows read-only data pages to be encoded and compressed. This also reduces storage usage by 50% to 90% compared with conventional storage engines such as InnoDB.
A Bloom filter is used to quickly determine whether the requested data exists, a succinct range filter (SuRF) is used to determine whether the range data exists, and a row cache is used to cache hot data rows to accelerate read operations.
Basic logic of LSM
All LSM-based write operations write data by appending the data to the memory. When the amount of data that is written reaches a specific amount, the data is frozen as a level and then flushed to the persistent storage. All rows to which data is written are sorted based on primary keys, regardless of whether the data is stored in the memory or in the persistent storage. In the memory, data is stored in a sorted in-memory data structure, such as a skip list or B-tree. In persistent storage, data is stored in a read-only, fully sorted persistent storage structure.
To allow a common storage engine to support transaction processing in common storage systems, you must add a temporal factor, based on which an independent view can be built for each transaction. These views are not affected in the event of concurrent transactions. For example, the storage engine sorts the transactions, assigns sequence numbers (SNs) that monotonically and globally increase to the transactions, and logs the SN of each transaction. This way, the storage engine can determine visibility among independent transactions and isolate transactions.
If data is continuously written to the LSM storage structure and no other operations are performed, the LSM storage structure eventually becomes the structure that is shown in the following figure.
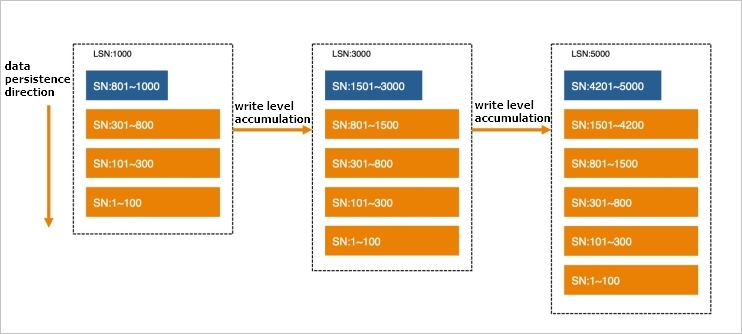
This structure facilitates write operations. A write operation is considered complete after the data is appended to the latest memory table. For crash recovery purposes, the data needs to only be recorded in the redo log. New data does not overwrite old data, and therefore appended records form a natural multi-SN structure.
However, when more persistence levels of data are accumulated and frozen, query performance decreases. The multi-SN records that are generated for different transaction commits but have the same primary key are distributed across different levels, as are the records that have different keys. In this case, read operations need to search all levels of data and merge the found data to obtain the final results.
Compactions are introduced to LSM to resolve this issue. Compactions in LSM have two objectives:
Control the hierarchy of LSM
In most cases, the data volume increases in proportion with the decrease of the LSM level to improve read performance.
Data access in a storage system is localized, and a large proportion of access traffic is concentrated on a small portion of data. This is the basic prerequisite for effective operations in the cache system. In the LSM storage structure, you can store hot data at a high LSM level on high-speed storage devices, such as NVMs and DRAMs, and cold data at a low level on low-speed storage devices that are provided at lower costs. This is the basis of hot and cold data separation in X-Engine.
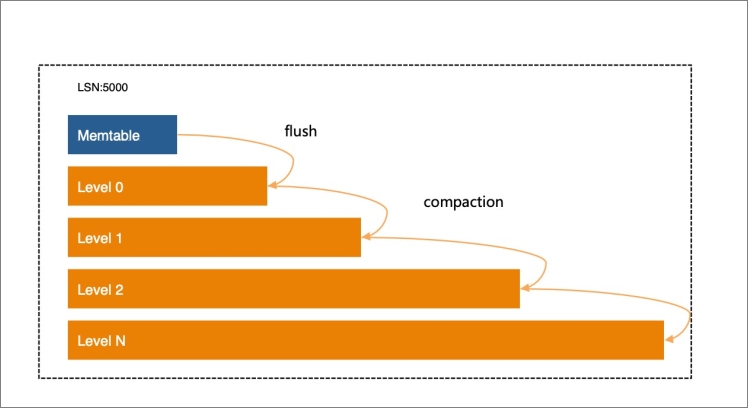
Merge data
Compactions continuously merge data at adjacent LSM levels and write the merged data to the lower LSM levels. During the compaction process, the system reads the data to be merged from two or more adjacent levels and then sorts the data based on keys. If multiple records with the same key have different SNs, the system retains only the record with the latest SN, discards the records with earlier SNs, and writes the record with the latest SN to a new level. The latest SN is greater than the earliest SN of the current transaction that is being executed. This process consumes a large number of resources.
In addition to the separation of hot data and cold data, factors such as the data update frequency must also be considered during compactions. Queries for a large number of multi-SN records waste more I/O and CPU resources. Therefore, records that have the same key but different SNs must be preferably merged to reduce the number of SNs. Alibaba Cloud designs a proprietary compaction scheduling mechanism for X-Engine.
Highly optimized LSM
In X-Engine, lock-free skip lists are used in the memory tables to accelerate highly concurrent read and write queries. A data structure must be planned at each LSM level to ensure the efficient organization of data at persistence levels.
Data structuring
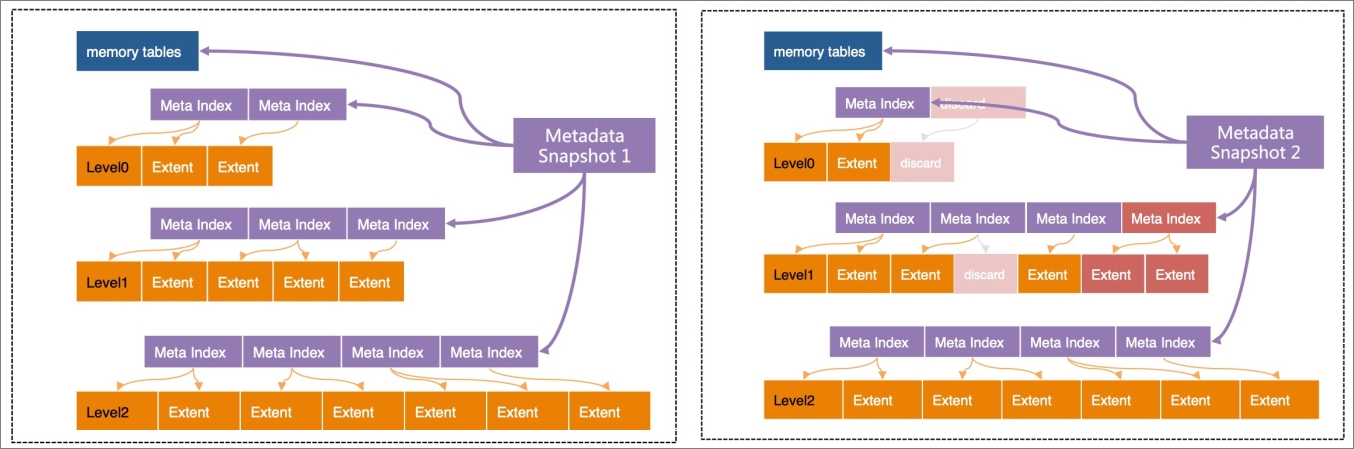
In X-Engine, each level is divided into extents of a fixed size. An extent stores the data with a continuous key range at the level. A set of metadata indexes are created for the extents at each level. All of these indexes together with all of the active and immutable memory tables form a metadata tree. The metadata tree has a structure similar to the structure of the B-tree, and the root nodes of the metadata tree are metadata snapshots. The metadata tree helps quickly locate extents.
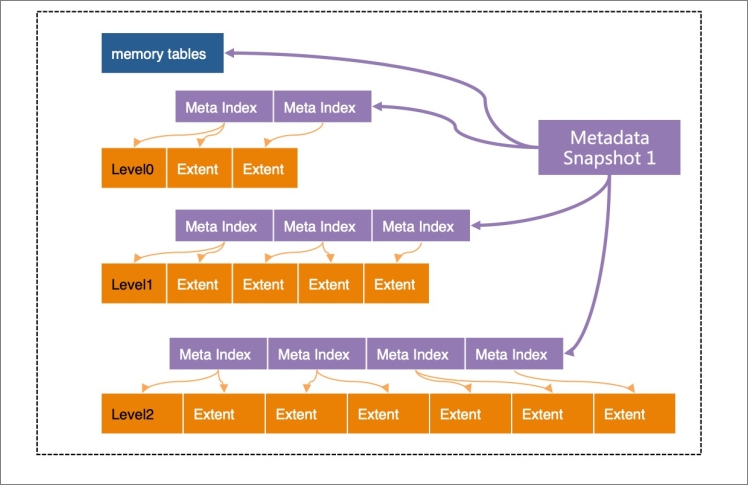
Except for the active memory tables to which data is being written, all structures in X-Engine are read-only and cannot be modified. When a point in time is specified, for example, when the log sequence number (LSN) is 1000, the structure that is referenced by metadata snapshot 1 in the preceding figure contains all data that is logged until LSN 1000. This is also why this structure is called a snapshot.
The metadata structure itself does not change after it is generated. All read operations start from this snapshot structure. This is the basis on which X-Engine implements snapshot-level isolation. The copy-on-write technique is used to perform all operations such as compactions and memory table freezes. The result of each modification is written to a new extent. Then, a new metadata index structure is generated. Finally, a new metadata snapshot is generated.
For example, each compaction generates a new metadata snapshot, as shown in the following figure.
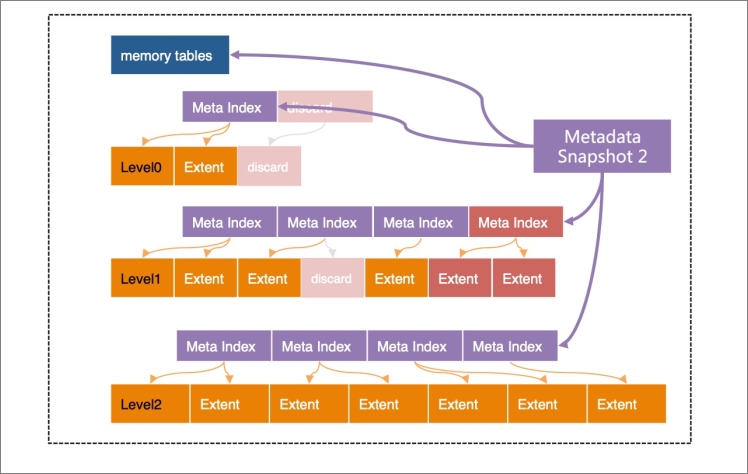
In this example, metadata snapshot 2 is slightly different from metadata snapshot 1. Only the leaf nodes and index nodes that change are modified.
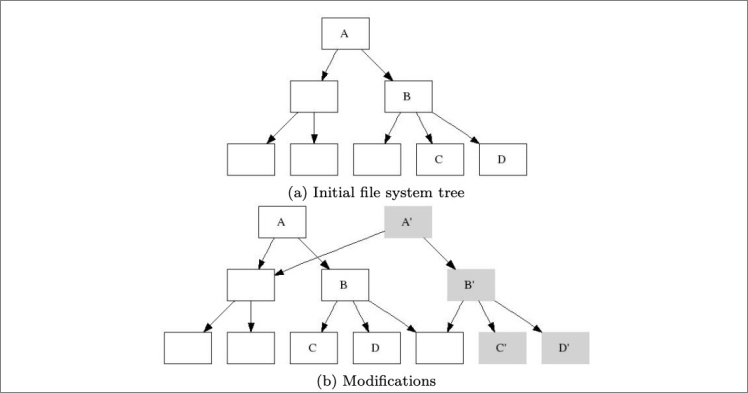
NoteThe data structuring technology is similar to the technology that is presented in the paper titled B-trees, shadowing, and clones. You can read the paper to better understand this process.
Transaction processing
With a lightweight write mechanism, LSM has significant advantages in processing write operations. However, transaction processing is not as simple as writing updated data to a system and requires complicated processing phases to ensure atomicity, consistency, isolation, and durability (ACID). X-Engine divides the transaction processing process into two phases:
Read and write phase
In the read and write phase, X-Engine checks for write-write conflicts and read-write conflicts and determines whether the transaction can be executed, rolled back, or locked. If no conflicts are detected, all modified data is written to the transaction buffer.
Commit phase
The commit phase includes the entire process of writing data to the write-ahead logging (WAL) file, writing data to the memory tables, committing data, and returning results to the user. This process involves I/O operations and CPU operations. I/O operations are performed to log operations and return results. CPU operations are performed to copy logs and write data to memory tables.
To increase the throughput during transaction processing, the system concurrently processes a large number of transactions. A single I/O operation requires high costs. Therefore, most storage engines preferably commit a number of transactions at a time, which is called "group commit." This allows you to combine I/O operations. However, the transactions that are to be committed at a time still need to wait for a long period of time. For example, when logs are being written to the disk, nothing else is done except to wait for the data to be flushed to the disk.
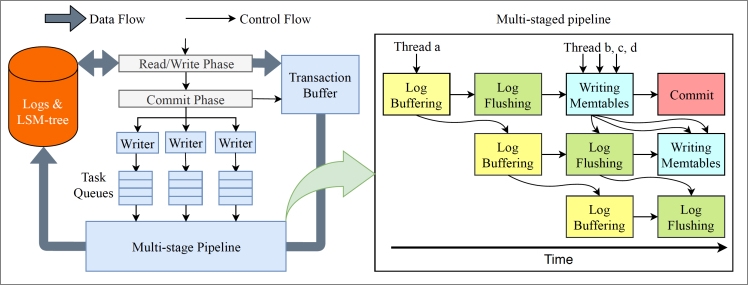
To further increase the throughput during transaction processing, X-Engine adopts a pipeline technology that divides the commit phase into four independent, more fine-grained stages:
Copying logs to the log buffer
Flushing logs to the disk
Writing data to the memory tables
Committing data
When a transaction commit thread enters the commit phase, it can freely choose any stages of the pipeline to process the data. This way, threads can concurrently process data at different stages. If the tasks for each stage are properly divided based on sizes, all stages of the pipeline can be nearly fully loaded. In addition, transaction processing threads rather than background threads are used in the commit phase. Each phase either executes tasks in a stage or processes requests. This process does not involve waiting or switching, and therefore the capabilities of each thread are fully utilized.
Read operations
In LSM, if multiple records with the same key have different SNs, the records with later SNs are appended to the record with the earliest SN. Records that have the same key but different SNs may be stored at different levels. The system must identify the appropriate SN of each requested record in compliance with the visibility rules that are defined based on the transaction isolation levels. In most cases, the system searches for records with the latest SNs from the highest level to the lowest level.
For single-record queries, the query process ends after the single record is found. If the record is located at a high level, for example, in a memory table, the record is quickly returned. If the record is located at a low level, for example, at a level used for random reading, the system must search downwards level by level. In this case, a bloom filter can be used to skip some levels to expedite the query. However, this involves more I/O operations. A row cache is used in X-Engine to expedite single-row queries. The row cache stores data above all persistent data levels. If a single-row query does not hit the requested data in the memory tables, the single-row query can hit the requested data in the row cache. The row cache needs to store each record with the latest SN at all persistence levels. However, the records in the row cache may change. For example, every time after a read-only memory table is flushed to a persistence level, the records in the row cache must be updated accordingly. This operation is subtle and requires a careful design.
For range scans, the level at which the data associated with a specific key range is stored cannot be determined. In this case, the final result can be returned only after all levels are scanned for the data and the data is merged. X-Engine provides various methods to address this issue. For example, SuRF presented at the best paper at the 2018 SIGMOD Conference provides a range scan filter to reduce the number of levels to be scanned. The asynchronous I/O and prefetching mechanism are also provided to address this issue.
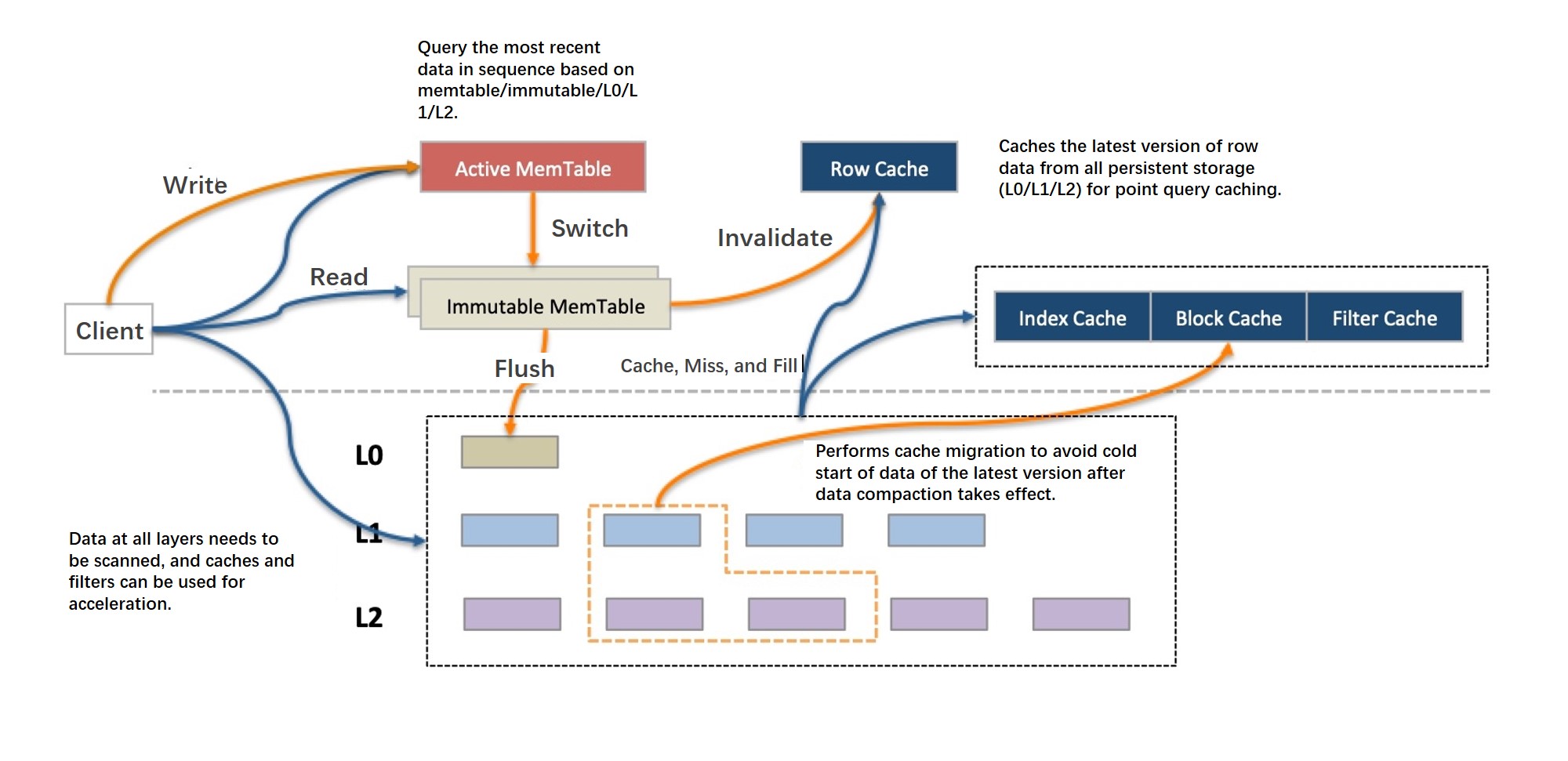
The core to read operations is the cache design. A row cache handles single-row queries. A block cache handles the requests that cannot be hit in the row cache or the range scan requests. However, in LSM, a compaction incurs updates to a large number of data blocks at a time. As a result, a large amount of data in the block cache expires within a short period of time, and a sharp performance jitter occurs. The following optimizations are made to address this issue:
Reduce the granularity of compaction.
Reduce the amount of data that is modified during each compaction.
Update the existing cached data only when the data is modified during each compaction.
Compaction
Compactions are important. The system needs to read data associated with overlapped key ranges from adjacent levels, merge the data, and write the merged data to a new level. This is the cost of simple write operations. The storage architecture of X-Engine is redesigned to optimize compactions.
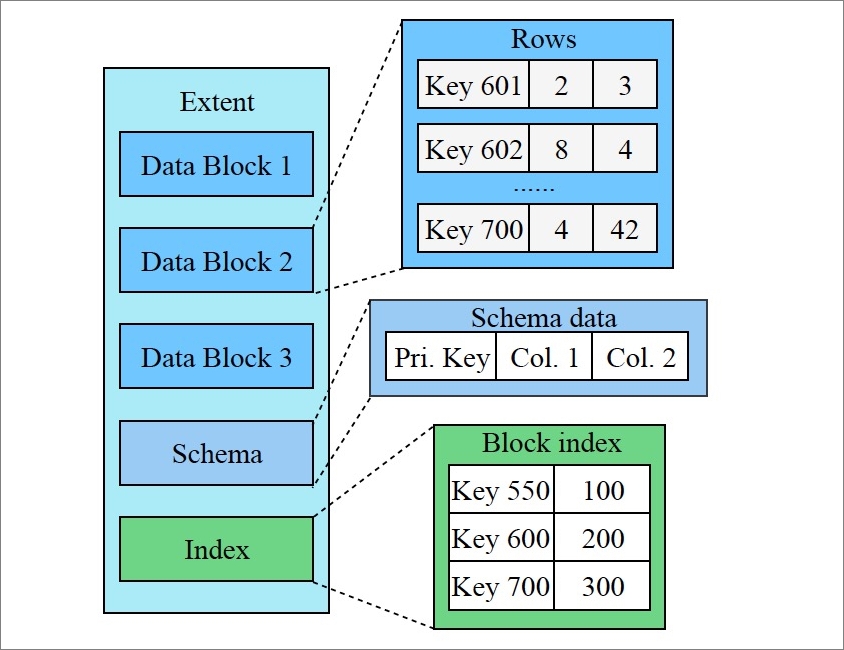
As previously mentioned, X-Engine divides each level of data into extents of a fixed-size. An extent is equivalent to a small but complete Sorted String Table (SSTable), which stores the data with a continuous key range at the level. A key range is further divided into smaller continuous segments, which are called data blocks. Data blocks are equivalent to pages in conventional databases, except that data blocks are read-only and their lengths are not fixed.
A comparison between metadata snapshot 1 and metadata snapshot 2 helps you understand the intent of the extent design. Only a small portion of overlapped data and the metadata index node need to be modified during each modification. The structures of metadata snapshot 1 and metadata snapshot 2 share a large number of data structures. This is called data reuse, and the extent size is a crucial factor that determines the data reuse rate. As a completely reusable physical structure, the extent size is minimized to reduce the amount of overlapped data. However, the extent size must be appropriate. If the extent size is abnormally small, a large number of indexes are required, which increases management costs.
In X-Engine, the data reuse rate is high in compactions. For example, you want to merge the extents that contain overlapped key ranges at level 1 and level 2. In this case, the merge algorithm scans the data row by row. All physical structures, including data blocks and extents, that do not overlap with the data at other levels can be reused. The difference between the reuse of extents and the reuse of data blocks is that the metadata indexes of extents can be modified while data blocks can only be copied. Data blocks are not recommended, although they can help significantly reduce CPU utilization.
The following figure shows a typical data reuse process in a compaction.
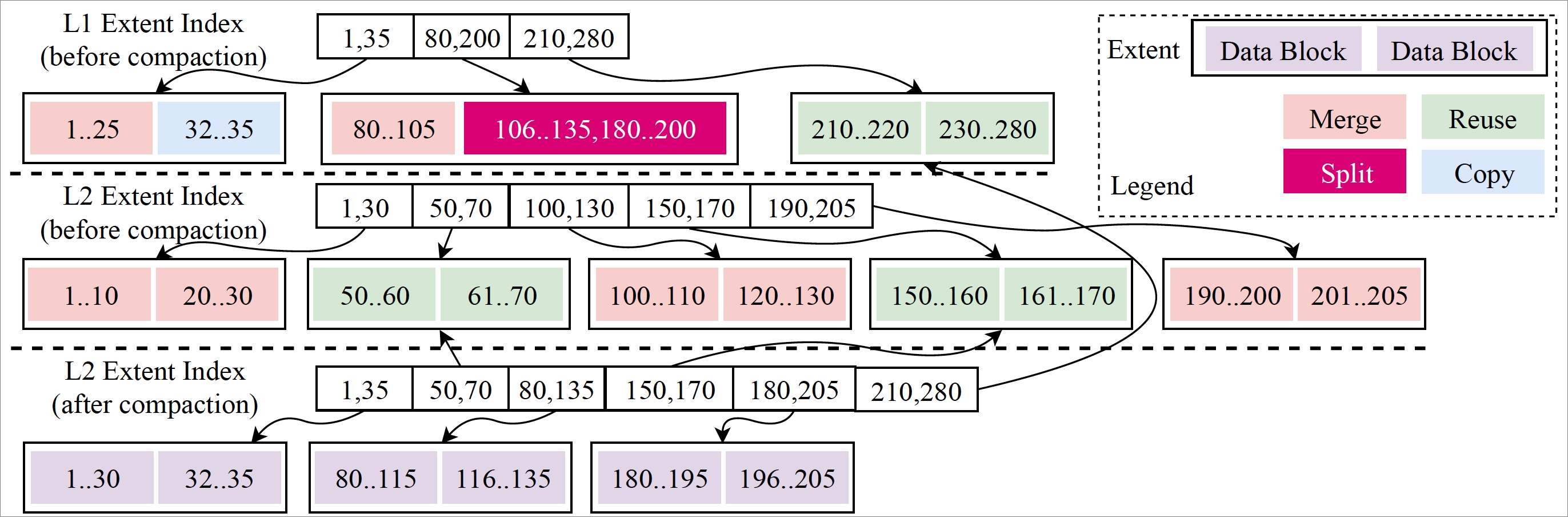
Row-by-row iteration is used to complete the data reuse process. However, this fine-grained data reuse causes data fragmentation.
Data reuse benefits the compaction itself, reduces I/O and CPU consumption during the compaction, and improves the overall performance of the system. For example, in the compaction process, data does not need to be completely rewritten, which significantly reduces the storage that is occupied by the written data. In addition, most data remains unchanged, and therefore the cached data remains valid after data updates. This reduces read performance jitters that are caused by the expiration of the cached data during the compaction.
In fact, optimizations to compactions are only part of what X-Engine does. X-Engine also optimizes the compaction scheduling policies, specifies the type of extent, and defines the granularity of compactions and the execution priorities of the specified compactions. These all affect the performance of the system. Although no perfect policies exist, X-Engine has accumulated valuable experience and defined a number of rules to define proper compaction scheduling policies.
Scenarios
For more information, see Best practices of X-Engine.
Get started with X-Engine
For more information, see Usage notes.
Follow-up development
As a storage engine for MySQL, X-Engine must be continuously improved in terms of compatibility with MySQL systems. Based on the most urgent needs, some features such as foreign keys will be gradually enhanced, and more data structures and index types will be supported.
The core value of X-Engine lies in cost-effectiveness. The continuous improvement of performance at lower costs is a long-term fundamental goal. Alibaba Cloud continues its exploration for new approaches that make X-Engine more efficient on operations, such as compaction scheduling, cache management and optimization, data compression, and transaction processing.